
Distributions
- Table of Contents
I. Hypergeometric distribution
Physical setup
Suppose we have a collection of objects which can be classified into two distinct categories. Denote the categories:
- Success ()
- Failure ()
Suppose that within these objects there exist of type and therefore of type . We choose objects without replacement, that is, we remove items in succession from the original set of . Let be a random variable representing the number of successes obtained. Then has a hypergeometric distribution.
Probability function
We require three values. Refer to the primer on combinations for a discussion on counting rules and notation.
First, we require the total possible number of ways that distinct items can be chosen from without replacement and where order does not matter. This is ‘ Choose ’
Second, we wish to know the number of ways that successes can be drawn from a total of
Third, we are left to select failures from a total of
Then the probability of selecting successes is
Examples
A Deck of cards
A deck of playing cards contains 4 suits (hearts, spade, diamonds,clubs) for each of 13 types {Ace, 2, 3,…, 10, King, Queen, Jack}. Deal 5 cards from the deck. The probability of selecting up to four Aces from the deck follows a hypergeometric distribution
# Probability of selecting Aces from a standard deck of cards
# Initialize our relevant variables
nAces <- 4 # Available aces
nOther <- 48 # Available non-aces
nDeal <- 5 # Number of cards dealt
aces <- 0:4 # The vector declaring the number of aces
# Use the dhyper built-in function for hypergeometric probability
probability <- dhyper(aces, nAces, nOther, nDeal, log = FALSE)
data <- data.frame( x = aces, y = probability )
# Bar plot
library(ggplot2)
ggplot(data, aes(x=factor(x), y=y)) +
theme(axis.text=element_text(size=14),
axis.title=element_text(size=18,face="bold"),
axis.title.x=element_text(margin=margin(20,0,0,0)),
axis.title.y=element_text(margin=margin(0,20,0,0))
) +
geom_bar(stat="identity", fill= "#2c3e50", colour="black") +
labs(x = "Number of Aces", y = "Probability")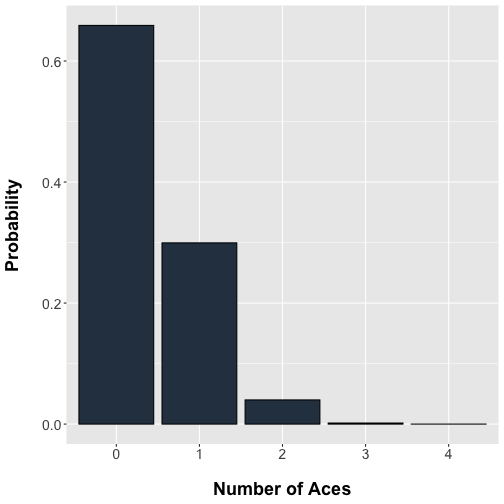
plot of chunk unnamed-chunk-1
II. Binomial distribution
Physical setup
Consider an experiment in which we have two distinct types of outcomes that can be categorized as
- Success ()
- Failure ()
Suppose the probability of success is and failure is . Repeat the experiment independent times. If is the number of successes then it has a binomal distribution denoted .
Probability function
We require three values. Refer to the primer on combinations for a discussion on counting rules and notation.
First, we require the total possible number of ways that successes can be arranged within experiments which is
Then the probability of each arrangement is multiplied times for successes and likewise for failures
Therefore,
Moments
The mean of a binomial distribution of sample size and probability is
The variance is
Comparison of hypergeometric and binomial
The key difference between the hypergeometric and the binomial distribution is that the hypergeometric involves the probability of an event when selection is made without replacement. In other words, the hypergeometric setup assumes some dependence amongst the selection of successes and failures. For example, choosing an ace from a deck and removing it reduces the probability of selecting a remaining ace. In contrast, the binomial distribution assumes independence and can be viewed as appropriate when event selection is made with replacement.
There are limiting cases where the hypergeometric can be approximated by the binomial. Consider the hypergeometric case where the total number of possible successes and failures is large compared to the number of selections . Then the probability of success does not appreciably upon selection without replacement. That is, for
Examples
A fair die
Toss a fair die 10 times and let be the number of sixes then .
# Probability of sixes in 10 tosses of a fair die
# Initialize our relevant variables
trials <- 10
sixes <- 0:10 # The vector declaring the number of successes
p <- 1/6 # The probability of a given face
# Use the dbinom built-in function for binomial probability
probability <- dbinom(sixes, size=trials, prob=p)
data <- data.frame( x = sixes, y = probability )
# Bar plot
library(ggplot2)
ggplot(data, aes(x=factor(x), y=y)) +
theme(axis.text=element_text(size=14),
axis.title=element_text(size=18,face="bold"),
axis.title.x=element_text(margin=margin(20,0,0,0)),
axis.title.y=element_text(margin=margin(0,20,0,0))
) +
geom_bar(stat="identity", fill= "#2c3e50", colour="black") +
labs(x = "Number of Sixes", y = "Probability")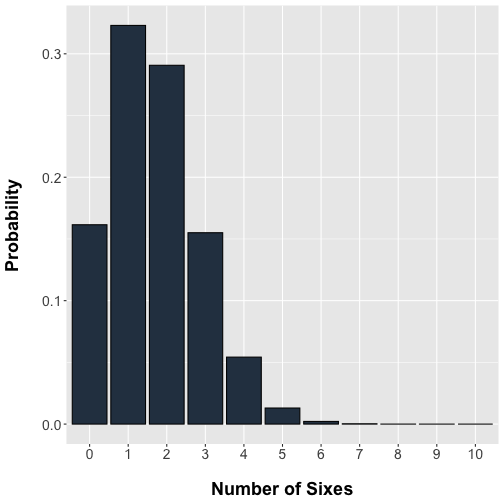
plot of chunk unnamed-chunk-2
III. Poisson distribution
Physical setup
Consider a limiting case of the binomial distribution as and but is fixed. This means that the event of interest is relatively rare. Then has a Poisson distribution .
Probability function
Since then and
Moments
The mean of a Poisson distribution with some sampling size and probability is
The variance is
Examples
The birthday game
Suppose that 200 people are at a party. What is the probability that 2 of them were born on December 25th? In this case and assuming birthdays are independent then and the mean
# Probability of two people born on December 25th
# Initialize our relevant variables
n <- 200 # The number of people
p <- 1/365 # The probability of a birthday on Dec. 25
mu <- n*p # The mean
# Use the dpois built-in function for Poisson probability
probability <- dpois(2, mu, log = FALSE)
probability## [1] 0.086791IV. Gamma distribution
Gamma function
Definition The gamma function os is
There are two nice properties of the gamma function that we will use.
Gamma distribution
Let be a non-negative continuous random variable. Then if the probability function is of the form
then has a gamma distribution . Typically, is called the ‘shape’ parameter and the ‘scale’ or ‘rate’.
V. Negative binomial distribution
Physical setup
The setup is very similar to the binomial. Consider an experiment in which we have two distinct types of outcomes that can be categorized as
- Success ()
- Failure ()
Suppose the probability of success is and failure is . Repeat an experiment until a pre-specified number of failures have been obtained. Let be the number of successes before the failure. Then has a negative binomial distribution denoted .
Probability function
There will be total trials but the last event is a failure so we really care about the first trials. There will be successes and failures in any order. Each order has a probability identical to a binomial trial .
Moments
The mean of a negative binomial distribution is
The variance is
The Poisson-gamma mixture
Count data such as RNA sequencing mapped reads is often modeled with a Poisson distribution where the mean and variance are equal to . However, there are cases where the variance exceeds that specified by the mean. To account for this ‘overdispersed’ data, the negative binomial distribution can be utilized. As we will show below, the negative binomial arises as a Poisson distribution where the Poisson parameter is itself a random variable distributed according to a Gamma distribution.
Let us state this in a more precise fashion. Suppose that we have distribution of counts that follows a Poisson distribution indexed by the parameter . Now suppose that is itself some function of another random variable where . Then the conditional distribution of the random variable of counts is
Let follow a gamma distribution with shape and scale .
The joint density of and is
Derive the marginal distribution of by integrating over the values of .
The key here is to transform the integrand into a gamma distribution with shape parameter and scale and noting that the integral over all values is unity.
It is simple to see that this result is the negative binomial with and . In this case the moments can be stated using these new variables.
From the moments of the negative binomial stated above, the mean is
The variance is
Alternative Poisson-gamma notation
This mixture model will be important in our discussion of RNA sequencing data differential expression testing. In this case the notation is altered where and is the ‘dispersion’ parameter for some counts of an RNA species . Also the gamma function is used to replace the binomial coefficients.
From the above discussion, we can restate the mean and variance.
Note that as the dispersion parameter approaches zero the negative binomial variance approaches the mean. Thus the dispersion parameter accounts for the extra variability over and above that expected with a Poisson.